

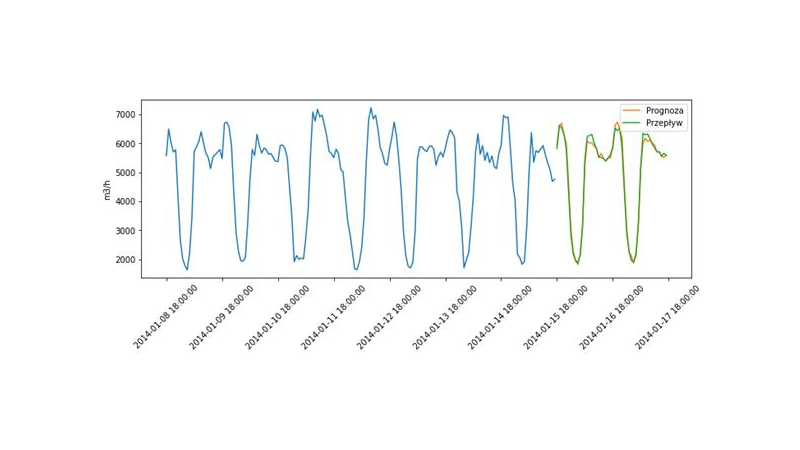
Stworzony model ma za zadanie prognozować chwilowy przepływ wody z dwóch przepompowni zarządzanych przez MPWiK Wrocław. Przepompownie zlokalizowane są na ulicy Na Grobli oraz na Mokrym Dworze. Do budowy modelu wykorzystano dane pomiarowe MPWiK oraz inne zbiory danych, w tym:
● przepływ chwilowy oraz ciśnienie w systemie;
● dane meteorologiczne, na które składają się takie informacje jak: temperatura, temperatura odczuwalna, ciśnienie, prędkość wiatru, wilgotność, opady i ich typ, zachmurzenie, grubość pokrywy śnieżnej;
● dane dotyczące dni wolnych od pracy, dni wolnych na uczelniach oraz w szkołach, imprez masowych (oznaczenie wystąpień);
● dane dotyczące obostrzeń i lockdown’ów, związanych z występowaniem na obszarze naszego kraju pandemii wirusa SARS-CoV-2 (COVID-19);
● dane dotyczące momentów wschodów i zachodów słońca;
Uzasadnienie wyboru danych:
W krótkoterminowej perspektywie prognoz na dobę i dwa dni w przód, najważniejszym czynnikiem wpływającym na zużycie wody są zbliżające się zdarzenia, zarówno pogodowe jak i socjalne. Dlatego też, model ten bazuje swoje prognozy nie tylko na historycznych odczytach przepływu chwilowego i ciśnienia, ale również na prognozie pogody, przewidywanych wydarzeniach oraz długości dnia.
Analizując literaturę i wspierając się znajomością Wrocławia i naszego klimatu, wybraliśmy zestaw zmiennych pogodowych, które mają wpływ na mobilność ludzi i ich potrzeby, a co za tym idzie - wpływa na zużycie wody. Ładna pogoda może zachęcić ludzi do wyjazdu na wycieczkę - co poskutkuje zmniejszonym zużyciem wody, ale też może zachęci kogoś do napełnienia basenu na działce - co poskutkuje zwiększeniem zużycia.
Duży wpływ na życie w mieście mają wydarzenia - imprezy masowe, te z kolei przyczyniają się do zwiększonego poboru wody. Taka informacja, stanowi tzw. kalendarz predykcji. W modelu znajduje się kilka kalendarzy, które pomagają modelowi rozpoznać nietypowe sytuacje - imprezę, dzień wolny od pracy, dzień wolny od szkoły i zajęć, ale również ostatnio bardzo istotną pandemię.
Rytm dobowy życia jest ważnym elementem codzienności i tak samo istotny jest dla zużycia wody. Długość dnia w ciągu roku we Wrocławiu zmienia się w ciągu roku o ponad 9 godzin i 40 minut, dlatego też różnica między zimowymi a letnimi wieczorami jest wyraźnie zauważalna, także w zużyciu wody w mieście.
Proces powstawania modelu:
Dane pozyskaliśmy z zasobów Hackathonu, modelu pogodowego ERA5 oraz za pomocą metod webscrappingu.
Zgromadzone dane w pierwszym etapie prac przetworzyliśmy do wspólnych ram czasowych: do danych pomiarowych MPWiK dołączyliśmy informacje z pozostałych zbiorów danych dla obszaru Wrocławia, zgodnie ze stemplami czasowymi.
Analizę danych rozpoczęliśmy od ich oczyszczenia i filtracji. Brakujące odczyty przepływów i ciśnienia, krótsze niż 3 godziny, zostały uzupełnione za pomocą funkcji spline. Na etapie inżynierii cech modelu - żeby wspomóc jakość prognoz, przekształciliśmy zmienne kategoryczne za pomocą kodowania one-hot. Informację o długości dnia przekształciliśmy do postaci binarnej informującej czy w danej godzinie była noc czy też dzień. Następnie wygładziliśmy tę informację w postać krzywej, która informować będzie model jak jest wcześnie po lub jak jest późno przed zachodem słońca. Dodatkowo, utworzyliśmy funkcje częstotliwościowe sinus i cosinus, które informują model o obecnej godzinie dnia i dniu tygodnia.
Zużycie wody składa się z kilku składowych, które można wyodrębnić metodami analitycznymi. Skorzystaliśmy z takiej metody by wydzielić z przepływu chwilowego trzy najważniejsze elementy zużycia wody: trend, cykliczność (tygodniowa / dzienna) oraz to co pozostało, czyli rezydua. Trend i cykliczność to składowe regularne, które łatwo przewidzieć. Dlatego też, całe prognozy skupiają się na rezyduach - to odchyły od cykliczności zużycia obserwowane w rezyduach są najważniejsze. Tren i cykliczność wymodelowaliśmy korzystając z funkcji spline i ekstrapolowaliśmy na okres prognoz - ta informacja została dodana później do przewidzianych rezyduów.
W celu maksymalizacji dostępnych danych, utworzyliśmy funkcję okna, wybierającego 4-tygodniowe (dla prognozy godzinowej) lub 2-tygodniowe (dla prognozy 10-minutowe) okresy nieprzerwanych danych z korkiem czasowym odpowiadającym rozdzielczości danych. Dane podzieliliśmy według poszczególnych lat (by uniknąć fałszywie podniesionej dokładności) na zbiór uczący i testowy, z uwzględnieniem aby do obu zbiorów trafiły dane również z okresu pandemii.
Prognozy wykonaliśmy w dwóch podejściach:
● krótkoterminowym - prognozy 10 minutowe dla 24 godzin w przód,
● długoterminowym - prognozy godzinowe na 2 dni w przód.
Do treningu algorytmu wykorzystaliśmy okno czasowe z horyzontem 7-dniowym dla prognozy długoterminowej oraz okno czasowe z horyzontem 3 dniowym dla prognozy krótkoterminowej. Testy pokazały, że jest to w zupełności wystarczające.
Nasze prognozy oparliśmy na uczeniu głębokim, korzystając z architektury Long-short time memory (LSTM). Skonstruowane tensory danych sieć przetwarza w swoich 2048 neuronach, które przekazują informacje do sieci gęsto połączonej, która z kolei dostosowana jest do tego by zwrócić całą prognozę na raz. Pomiędzy warstwą LSTM i gęstą dodano mechanizm resetowania wag, który zapobiega nadmiernemu wpasowaniu modelu, który jest częstym problemem w tej dziedzinie. Dodatkowo, zastosowaliśmy mechanizm wczesnego zatrzymania, który wstrzymuje trening sieci, kiedy w kolejnej iteracji nie ma już zysku dokładności. Sieć uczyła i walidowała się na 5000 przypadkach - danych podzielonych w stosunku 80%/20%.
Wyniki
Naszą sieć sprawdziliśmy na zbiorze testowym, losowo wybranych 1000 przypadkach. Do zmierzenia jej dokładności wykorzystaliśmy miary średniego bezwzględnego błędu absolutnego (MAPE) oraz indeks Nash-Sutcliffe, często stosowany wskaźnik “dobroci” modelu prognostycznego.
Comments (0)