



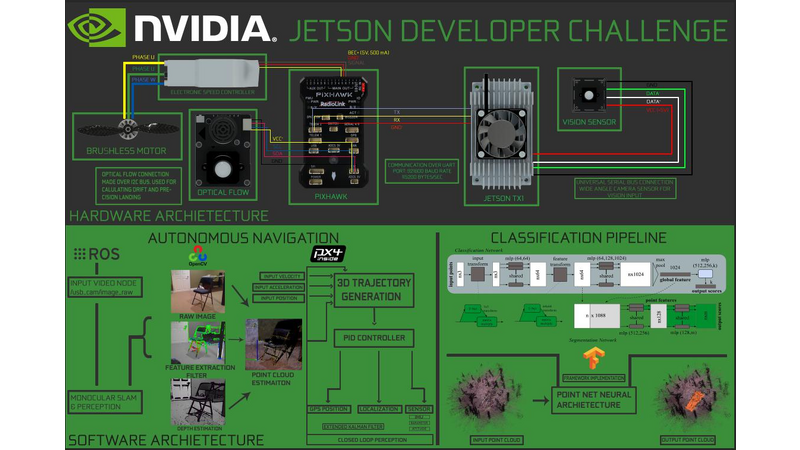
TITUS is an autonomous Unmanned Aerial Vehicle (UAV) focused on inspecting forests to determine areas of possible risk to wildfires. To accomplish this task of classifying the hazardous areas, we focused on developing a UAV that can navigate through a dense forest environment autonomously, classify areas of risk to wildfires, and be cost effective at the same time. The main feature of TITUS that differentiates itself from any other autonomous UAVs is that it only has one camera as its perception sensor for Simultaneous Localization and Mapping (SLAM). This can only be possible with the on board GPU that the Jetson platform provides along with the NVIDIA CUDA API. The next section will explain how we are able to develop real time depth maps with a single monocular camera.
MonoSLAM:
We have developed a novel approach to achieving Simultaneous Localization and Mapping (SLAM) from a single moving camera. This approach uses two inputs to an extended Kalman Filter to generate a probabilistic depth measurement on a per-pixel basis. The first input is an implementation of REMODE SLAM developed by Professor Scaramuzza, Christian Forster, and Matia Pizzoli. This approach combines Bayesian Estimation and convex optimization for image processing. Uncertainty is computed to reject erroneous estimations and provide live feedback to the depth map reconstruction. Camera pose estimates are computed in the following sequence of steps, every time step k, the pose of the camera T(k,r) in the depth map reference frame is calculated by utilizing visual based odometry. We build upon this method by extracting the inertial measurement unit navigation messages from our flight controller and publishing those messages as a ROS node. Since visual odometery is the main contributor to the probability of the depth measurement, utilizing ground truth estimates from the Pixhawk (this is the brand of our flight controller) allows our model to tend more towards a deterministic measurement. As the camera pose is updated, the transform of the plane is mapped to depth viewer and checked for error threshold. The other input is the output of a linear regression calculation that is done to predict the depth of a pixel in an image. The regression is trained on a data set of rgb-d data which takes into account the light threshold in the image, the true depth to each pixe,l and the rgb channel values of each pixel. Since our deployment environment is in a forest, we make the assumption that we can ignore drastic changes in light for most conditions. As a result we only weigh the estimation of the regression ⅕ of the REMODE estimation. We have seen great results for areas of low light with this method.
3D Classification of underbrush:
In order to classify underbrush from our generated 3D scans, we utilize Point Net. A deep learning framework developed by Stanford University for deep learning on geometric data structures. This includes the segmentation and classification of objects in point cloud data. On the backed for part segmentation of the generated map, a volumetric convolutional neural network is used to detect and segment the part. We collected a medium sized amount of 3D scans utilizing our MonoSlam algorithm to collect data of underbrush to train the network. We also optimized the architecture design to run on the Jetson for classification of underbrush in real time.
Comments (3)
j
janajaber4433
a
alkuran
v
vinnysilmi